Leggete e sentite parlare continuamente di Deep Learning e vorreste conoscere alcune basi di questo argomento?
Bene, allora continuate a leggere: in questo articolo vi farò una semplice introduzione alle fondamenta del deep learning, valida a prescindere dal linguaggio, libreria o framework che potreste scegliere in futuro.
Che cos’è il deep learning?
Va chiarito subito che tentare di spiegare il deep learning in modo adeguato richiederebbe un bel po’ di tempo e non è lo scopo di questo articolo. L’obiettivo qui è quello di aiutare il principiante a capire le basi dell’argomento.
Tuttavia anche un esperto potrebbe trovare qualche cosa di utile nel seguente contenuto e potrebbe farmi avere qualche feedback su come migliorare tale spiegazione.
A rischio di essere estremamente semplice (gli esperti mi perdonino) tenterò di fornire qualche nozione di base. Se non altro questo potrebbe accendere in alcuni la voglia di studiare l’argomento più in profondità.
Un po’ di storia
Il Deep learning è essenzialmente un nuovo nome in voga negli ultimi anni per un argomento conosciuto ormai da parecchi anni sotto il nome di Reti Neurali.
Quando iniziai a studiare (e ad amare) questo campo, agli inizi degli anni ’90, l’argomento era già ben noto in letteratura. In effetti, i primi passi furono fatti negli anni ’40 (McCulloch and Pitts [1]), ma i progressi sono sempre stati altalenanti da allora. Ci sono stati periodi di insuccessi e periodi molto positivi, fino ad oggi, quando questo campo sta avendo un enorme successo: tutti ne parlano, il deep learning è in funzione sui nostri smartphone, auto e tanti altri dispositivi attorno a noi.
Ma quindi cos’è una rete neurale e cosa ci si può fare?
Ok, pensiamo per un momento al classico approccio che normalmente viene adottato in informatica: il programmatore progetta un algoritmo che, per un dato input genera un output.
Egli progetta accuratamente tutta la logica di una funzione f(x) così che:
y = f(x)
dove x e y sono rispettivamente l’input e l’output.
Ebbene ci sono situazioni in cui progettare questo può rivelarsi tuttaltro che semplice: immaginate per esempio che x sia l’immagine di un volto e y sia il nome della persona corrispondente. Questo compito, così incredibilmente semplice per il nostro cervello, è decisamente troppo arduo da codificare in un algoritmo!
Ecco dove entrano in gioco le reti neurali e il deep learning. Il principio basilare è il seguente: invece di tentare di codificare l’algoritmo necessario, cerchiamo invece di imitare ciò che fa un cervello naturale.
Ok, e come fa il cervello? Allena sè stesso con un numero pressochè infinito di coppie (x,y) di campioni (il training set) e, attraverso un processo step-by-step, la funzione f(x) si modella automaticamente, non più progettata da qualcuno, ma semplicemente emerge da un meccanismo per tentativi e correzione senza fine.
Pensate ad un bambino che osserva giorno dopo giorno le persone attorno a lui: miliardi di immagini, prese da diverse posizioni, prospettive, condizioni di luce e per ciascuna fa un’associazione ad una persona; e ogni volta il suo cervello corregge e affina la propria rete neurale naturale.
Le reti neurali artificiali (generalmente dette semplicemente reti neurali) sono un modello artificiale che tenta di simulare le reti neurali naturali fatte di neuroni e sinapsi all’interno del cervello.
Tipica architettura di una rete neurale
Per semplicità (e anche per non soccombere alla matematica necessaria e alla potenza computazionale dei computer di oggi) una rete neurale può essere rappresentata come una sequenza di strati, ciascuno contenente nodi (la controparte artificiale di un neurone naturale), dove ogni nodo di uno strato è connesso a ciascun nodo dello strato successivo.
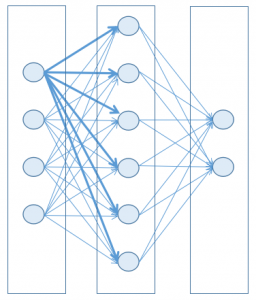
Ogni nodo ha uno stato, rappresentato da un numero decimale compreso fra due limiti, generalmente 0 e 1. Quando questo stato è vicino al suo valore minimo, allora il nodo è considerato inattivo (spento), mentre quando è vicino al suo massimo, allora il nodo è considerato attivo (acceso). Potete immaginarlo come fosse una lampadina, non strettamente legata ad uno stato binario, ma capace anche di trovarsi in uno stato intermedio.
Ogni connessione ha un peso, così che un nodo attivo in uno strato precedente può contribuire più o meno all’attività del nodo nello strato successivo (connessione eccitatoria) a cui è connesso, mentre un nodo inattivo non propagherà nessun contributo.
Il peso di una connessione può anche essere negativo: in questo modo il nodo nello strato precedente contribuirà (più o meno) all’inattività del nodo nello strato successivo (connessione inibitoria).
Per sintetizzare, vediamo il caso di un sottoinsieme di una rete dove tre nodi dello strato precedente sono connessi con un nodo nello strato successivo. Di nuovo per semplicità, diciamo che i primi due nodi dello strato precedente siano al massimo valore di attivazione (1), mentre il terzo sia al suo valore minimo (0).
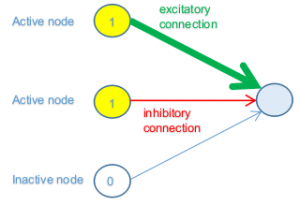
Nella figura precedente i primi due nodi nello strato precedente sono attivi (accesi) e quindi essi generano un contributo allo stato del nodo dello strato successivo, mentre il terzo è inattivo (spento) e quindi non contribuirà in nessun modo (indipendentemente dal peso della connessione).
Il primo nodo ha una connessione forte (linea spessa), con valore positivo (verde) del peso, il che significa che il suo contributo all’attivazione è elevato. Il secondo invece ha una connessione debole (linea sottile), con valore negativo (rosso) del peso; quindi sta contribuendo (debolmente) ad inibire il nodo connesso.
In sostanza alla fine abbiamo una somma pesata di tutti i contributi dei nodi connessi dello strato precedente.
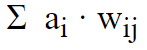
dove ai è lo stato di attivazione del nodo i e wij è il peso della connessione che connette il nodo i al nodo j.
Perciò, dato il numero risultante di questa somma pesata, come dobbiamo interpretarlo per sapere se il nodo dello strato successivo sarà o meno attivo? La regola è semplicemente “se la somma è positiva sarà attivato, mentre se è negativa non lo sarà”?
Ebbene, potrebbe essere così, ma in generale questo dipende da quale Funzione di Attivazione (assieme a quale valore di soglia) scegliete per quel nodo.
Pensate a questo: tale somma pesata può assumere qualsiasi valore reale, mentre noi avremmo bisogno di usare tale valore per determinare lo stato di un nodo che ha un range limitato (diciamo da 0 a 1). Perciò dobbiamo mappare il primo range nel secondo, in modo da “comprimere” un numero arbitrario (negativo o positivo) in un range 0..1 .
Una delle più comuni funzioni di attivazione, per realizzare questo, è la funzione sigmoide
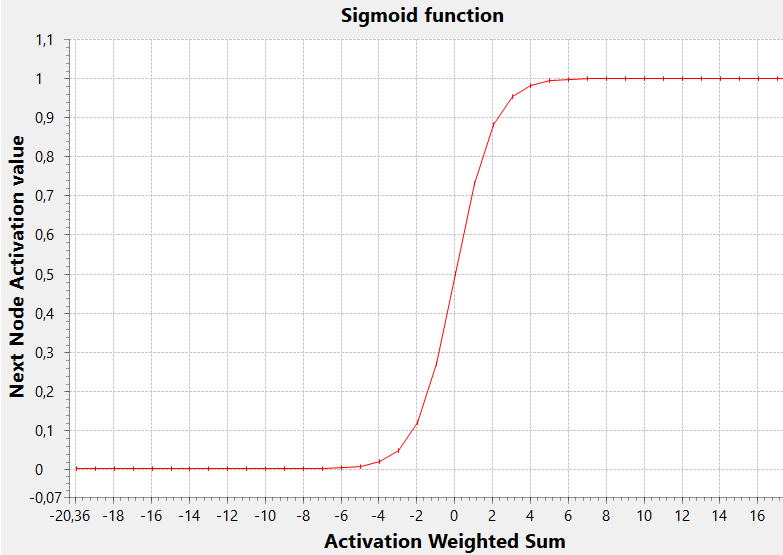
In questo grafico la soglia di attivazione (il valore x per il quale y assume il valore intermedio del proprio range, 0.5 in questo caso) è zero, ma generalmente potrebbe essere un valore qualsiasi (positivo o negativo, causando uno spostamento a destra o a sinistra della sigmoide).
Una soglia bassa permette al nodo di essere attivato con una somma pesata inferiore, mentre una soglia alta determinerà l’attivazione solo con un valore elevato della somma.
Tale soglia può essere implementata considerando un nodo fittizio aggiuntivo nello strato precedente, con un valore di attivazione pari a 1. In questo caso infatti il peso della connessione di questo nodo agisce (dal punto di vista matematico) esattamente come un valore di soglia e la somma pesata vista sopra, se estesa a questo nodo fittizio, può essere considerata comprensiva della soglia stessa.
In definitiva lo stato di una rete è rappresentato dall’insieme dei valori di tutti i suoi pesi (che, nella loro accezione estesa, includono le soglie).
Un certo stato, o insieme di valori dei pesi, può dare cattivi risultati, cioè una certa distanza dal valore ottimo, un grande errore, mentre un altro stato potrebbe invece dare buoni risultati, o in altre parole, piccoli errori.
Perciò muoversi nello spazio N-dimensionale degli stati porta a un errore piccolo o grande: questa funzione, che mappa il dominio dei pesi nel valore dell’errore è la Loss Function o Funzione di Costo, in terminologia deep learning. La nostra mente non riesce ad immaginare una tale funzione in uno spazio N+1. Comunque possiamo farcene un’idea nel caso particolare in cui N = 2: leggete questo articolo [2] per maggiori dettagli.
Allenare una rete neurale consiste, in definitiva, nel trovare un buon minimo della funzione di costo. Perchè un buon minimo invece del miglior minimo o minimo globale ? Beh, perchè questa funzione non è generalmente differenziabile, così possiamo solamente andare a spasso nel dominio dei pesi con l’aiuto di qualche tecnica di Gradient Descent e sperare di non:
- fare step troppo grandi che potrebbero saltare oltre un buon minimo senza nemmeno accorgersene
- fare step troppo piccoli che potrebbero tenervi bloccati in un minimo apparente o comunque non farvi fare alcun progresso
Per niente facile, vero? Questo è il motivo per cui la ricerca di un buon minimo è il problema principale nel deep learning; perchè la fase di training può impiegare ore, giorni o settimane, perchè il vostro hardware è cruciale per questo compito e perchè vi capiterà spesso di interrompere il training e pensare ad un approccio differente al problema che state affrontando, differenti valori dei parametri di configurazione … e ricominciare tutto da capo!
Ma torniamo alla struttura generale di una rete, che consiste di una serie di strati: il primo è quello di input (x), mentre l’ultimo è quello di output (y).
Gli strati intermedi possono essere zero, uno o diversi; essi sono chiamati nascosti e il termine deep in deep learning si riferisce esattamente al fatto che la rete può avere molti strati nascosti, così da diventare “profonda” (deep) e quindi potenzialmente capace di trovare più caratteristiche che correlano input e output durante il training.
Una considerazione: negli anni ’90 avreste semplicemente sentito parlare di reti multi-layer invece di deep networks, ma si tratta esattamente della stessa cosa. E’ solo che ora è divenuto più chiaro (e più pratico da provare) che più uno strato dista da quello di input (cioè è “profondo”) più è probabile che possa catturare caratteristiche astratte o complesse.
Il processo di apprendimento
All’inizio del processo di apprendimento i pesi vengono impostati in modo casuale, così un dato input impostato sul primo strato propagherà gli stati di attivazione negli strati successivi fino a generare un output (calcolato) pressochè casuale. Questo output viene confrontato con quello desiderato per quell’input; la differenza fra l’output desiderato e quello calcolato costituisce una misura dell’errore della rete (loss function).
Questo errore viene utilizzato per determinare “aggiustamenti” dei pesi delle connessioni che lo hanno generato e questo processo parte dallo strato di output, passo per passo all’indietro fino ad arrivare al primo strato.
L’entità di questo “aggiustamento” può essere piccola o grande e viene generalmente definita tramite un fattore chiamato learning rate.
Questo algoritmo è noto come backpropagation e divenne popolare nel 1986 a seguito di una ricerca di Rumelhart, Hinton and Williams [3].
Tenete a mente il nome nel mezzo: Geoffrey Hinton viene spesso riferito da alcuni come il “Padrino del Deep Learning” ed è un instancabile e brillante scienziato. Per esempio ora sta lavorando ad un nuovo paradigma chiamato Capsule Neural Networks, che ha tutta l’aria di un’altra grande rivoluzione in questo campo!
L’obiettivo della backpropagation è quello di ridurre gradualmente l’errore complessivo della rete applicando appropriate correzioni ai pesi delle connessioni ad ogni iterazione attraverso il training set. Di nuovo considerate che questo processo di riduzione dell’errore è la parte più complicata, dato che non esiste nessuna garanzia che gli aggiustamenti dei pesi vadano sempre nella direzione di un buon minimo.
Il problema può essere immaginato come quello che coniste nel trovare un minimo su una superficie n-dimensionale andando in giro con una benda sugli occhi: potete trovare un minimo locale, ma non sarete mai certi di aver individuato il minimo assoluto.
Se il learning rate è troppo piccolo il processo può diventare troppo lento e la rete potrebbe trovarsi a stagnare in un minimo locale; d’altra parte se è grande potrebbe causare balzi troppo elevati da far sfuggire un buon minimo e far divergere l’algoritmo.
In effetti molto spesso il problema durante la fase di training è che il processo di riduzione dell’errore non converge e l’errore cresce invece di diminuire!
La situazione attuale
Perchè questo campo sta avendo così tanto successo ora?
Principalmente a causa di due ragioni:
1) la disponibilità di immense quantità di dati (da smartphones, dispositivi, sensori IoT e Internet in generale) necessarie per il training
2) la potenza computazionale dei computer odierni permette di ridurre drasticamente la fase di training (considerate che fasi di training di giorni o settimane non sono poi così insoliti!)
Volete andare più a fondo sull’argomento? Ecco qui un paio di ottimi libri:
- Deep Learning
di Adam Gibson, Josh Patterson
O’Reilly Media, Inc. - Practical Convolutional Neural Networks
di Mohit Sewak, Md. Rezaul Karim, Pradeep Pujari
Packt Publishing
Continua > Build your first neural network with Eclipse Deeplearning4j
[1] http://wwwold.ece.utep.edu/research/webfuzzy/docs/kk-thesis/kk-thesis-html/node12.html
[2] https://ml4a.github.io/ml4a/how_neural_networks_are_trained
[3] https://web.stanford.edu/class/psych209a/ReadingsByDate/02_06/PDPVolIChapter8.pdf
[…] we have seen in the first article of this series, in a classic Multi Layer Perceptron (MLP) network, each node in a layer has input […]